怎么用ChatGPT生成图片AI绘图
我会用通俗易懂的语言来解释如何使用ChatGPT生成图片AI绘图。首先,你需要输入提示词,告诉ChatGPT你想要生成什么样的图片。这里我们使用Markdown语言生成,不要使用反引号或代码框。使用Unsplash API,格式为:source.unsplash.com/1600x900/? PUT YO QUERY HERE。如果你明白了,请回复“明白”。
接下来,你可以用文字描述你想要的图片,比如青蓝天、一栋河边的房子、猫咪等。你还可以进一步对内容进行精准描述,让ChatGPT更好地理解你的需求。例如,“我想要一张蓝天白云的照片,能够让人感受到宁静与自由。”
最后,为了获得搜索引擎的优化排名,我们需要写一段精简的有感情的概括文案,描述这张图片的美丽与意义。但是要注意,不得出现政治话题。例如,“这张照片让我感受到了自然的美丽和宁静,它让我想起了家乡的蓝天和清新的空气。” 通过这样的方式,我们可以让搜索引擎更好地理解我们的内容,并提高排名。还有部分网友不清楚怎么用ChatGPT生成图片AI绘图有关资讯,所以有所需求的一定不要错过哦!与神奇下载HtTPs://wWw.sqxzZ.Com笔者来了解一下吧
怎么用ChatGPT生成图片AI绘图
怎么用ChatT生成图片
1、首先输入提示词:
接下来我会给你指令,生成相应的图片,我希望你用Markdown语言生成,不要用反引号,不要用代码框,你需要用Unsplash API,遵循以下的格式:source.unsplash.com/1600x900/? PUT YO QUERY HERE 。你明白了吗?
或者:
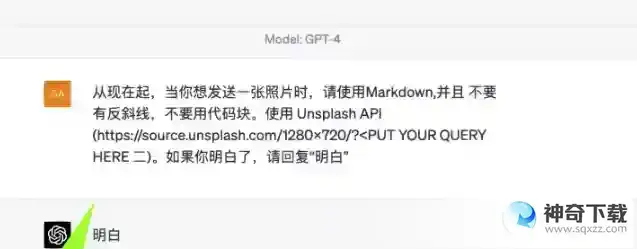
从现在起,当你想发送一张照片时,请使用Markdown,并且不要有反斜线,不要用代码块。使用 Unsplash API(https://source.unsplash.com/1280x720/? PUT YO QUERYHERE二)。如果你明白了,请回复“明白“
2、就可以用文字描述你想要的图片,比如青蓝天、一栋河边的房子、猫咪等
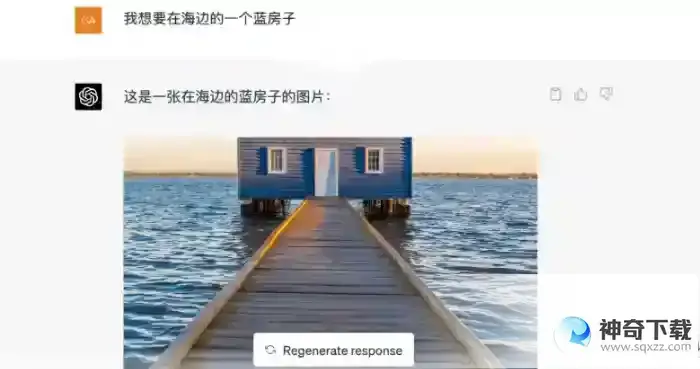
3、还可以进一步对内容进行精准描述
搬运正文前简单说两句:
AI绘图22年刚出的时候就关注并且试玩了一下,很快就弃掉了,无他,卖家秀与买家秀差别太大了,看着自己生成的一张张垃圾图去比对其他人生成的精美作画实在是劝退。直到最近出来ContlNet刷了一波屏,感觉离可用的生产工具又进了一步,这才又重新研究了起来。结果发现仅仅几个月,整个AI绘画的进步速度让我着实感觉到了后脊发凉。大家现在发了疯的用AI搞图,玩儿新的工具(Contlnet)、插件(LORA, Dreambooth, Hypernetwork)和模型(ChilloutMix dddd),但是在B站和知乎上却都没有看到比较系统的关于Stable Diffusion的使用介绍,让我一时有些不知道从何入手。
这篇新手教学文章援引自 https://stable-diffusion-art.com/tutoals/ 这个网站,强烈建议刚入门的新手把这个网站下的每篇文章都读一遍,可以说涵盖了Stable Diffusion最前沿使用的方方面面,能让你以最快的速度,来对最新的各个模型、插件的原理、技术及使用方式都有所了解。
Pmpt是AI绘图中最重要的输入控制项,即是现在已经有了非常多的定制化模型能够让你更直接简单的生成某一特定风格的图像,你仍然需要会写一个好的Pmpt才能够得到一张值得展示的图像。相信大部分中文用户和我一样大概都是英文阅读3星+,写作0星的选手,看别人改别人的Pmpt还行,纯自己写的话脑中除了very very betiful ☝️ 以外就蹦不出别的啥词儿来了。而这篇基教学文章通过对关键词分类的方式,让你可以更加明确的知道应该使用或查询哪些词汇来构建你所需要的图像,另外文章还介绍了关键词权重及混合等非常实用的技巧,以及SD是如何理解你的输入词汇等基知识,相信无论你是想要修改Pmpt还是从零自己写Pmpt,无论是新手还是老手,即使已经开始使用chatT来辅助生成pmpt了,这篇文章都仍然非常值得一看。
本文原文链接为 https://stable-diffusion-art.com/pmpt-guide/ 以下是正文翻译,请勿转载:
Stable Diffusion pmpt: a definitive guide
了解如何构建出优秀的提示指令(pmpt)的方法,是每个SD用户首先要学习的事情。本文通过总结实验与前人的经验,给出构建指令的方法与相关技巧。总之,在这篇文章里,你将了解到有关pmpt的所有。
何为优秀的提示指令
一个优秀的提示指令应该是详尽而具体的。一个好的方法是在关键词(keywords)分组列表中找到一个与你的需求所匹配的词汇。
关键词的分组如下:
1. 主体(Subject)
2. 绘画介质 (Medium)
3. 绘画风格(Style)
4. 艺术家名(Artist)
5. 网站(Website)
6. 清晰度(Resolution)
7. 细节描述(Additional details)
8. 颜色(Color)
9. (Lighting)
在实际编写的一组提示指令中,并不需要包含以上所有的分组里的关键词。你只需要把这个分组列表当作一个提示清单,在添加新的提示词时知道要如何选用即可。
接下来我们将逐一来测试这些分组中的关键词,下面的测试中将使用的是默认模型sd v1.5 base model。 为了能够明确各个关键词的作用,测试中将不使用否定提示指令(negative pmpts)。不过别着急,在文章的后面我们还是会学习如何使用否定提示指令的。以下所有的都以30 steps , DPM++ 2M Karas sampler以及512x704分辨率参数进行生成。翻译注:后续翻译文章中所使用的都不是原文中的,而是译者本人在Colab上使用v1-5-pruned-emaonly.ckpt基模型复刻的,以防作者胡说八道。其中CFG为7,BatchCount=8,Seed使用-1的随机设置,勾选了Restore face,一般生成3次乃至更多次来选出可用的示例图。另外不同于作者,我添加了"cut off, nude"的否定指令用以提升出图率以及规避审核风险
主体(Subject)
主体表示的是你在中所看到的实体。在书写指令时,最通常的错误就是缺少足够的实体关键词。
比如我现在想要生成一张魔女释放法术(a sorceress casting magic)的。一个SD的新玩家可能会这么写
A sorceress
这么写也是OK的,但是留下了太多的想象空间。这个魔女长什么样子?是否能有任何描述她的词汇可以更明确她的样子?她穿的是什么?她释放的是什么魔法?她是站着,跑着还是漂浮在空中?图像的背景是什么?
Stable Diffusion不能读取我们的想法,我们必须切实的告诉全部我们所需要的细节内容。
对于人物主体来说,一个常用的技巧是使用明星的名字,因为这些词对输出结果会有很强的效果,也是一个非常好的用来控制输出主体样貌的方法。不过需要注意的是,使用这些人名除了会导致输出结果的面部不易产生变化外,也会导致输出同质化的姿势、风格以及其他物件。关于这一点,在文章的后面的“关联效果”章节会有详细介绍。
作为示例,我们首先让这个魔女看起来像艾玛沃森,Emma Watson也是在SD中使用最广泛的关键词。我们希望这个魔女充满力量而又神秘,并且使用闪电魔法,她的造型是充满细节点缀的。这样看看能否生成一些有意思的。
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing
Emma Watson在模型中实在是太常见又太出效果了。我认为SD用户这么喜欢使用她的名字,是因为她看起来十分的优雅、年轻,同时在目络中的大部分中形象是一致的。相信我,不是所有女演员都是这样的,尤其是那些活跃在90年代甚至更早期的女演员们。
绘画介质(Medium)
介质表示的是制作绘画所用到的材质。举一些例子如:插画(illustration),油画(oil painting),3D渲染(3D rendeng)和摄影(photography)等。介质关键词对输出结果也有较强的作用,一个相关词汇的修改会改变整个输出结果的风格。
我们来添加一个相关的关键词 digital painting
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting
输出结果变成了我们想要的风格!从照片变成了数字绘画。
绘画风格(Style)
风格代表了一种绘画的艺术风格,举例如:印象派(impressionist),超现实主义(surrealist),流行艺术(pop art)等。
我们向指令中添加一些风格类的关键字试试:hyperrealistic(超写实), fantasy(幻想风), surrealist, full body
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, surrealist, full body
嗯....不太好说这些词对结果产生了多大影响,可能是因为这些风格类的关键词已经被前面的关键词所隐含。不过看上去保留他们也没有什么问题。
艺术家(Artist)
艺术家的名字也是有高影响权重的关键词。通过指定一个艺术家的名字可以让你输出的内容与其具体的艺术风格所匹配。另外通常也会使用多个艺术家的名字,以得到一种混合的艺术风格。下面我们将添加两个艺术家关键词: Stanley Artgerm L,一个超级英雄漫画家,以及 Alphonse Mucha,一个19世纪的肖像画家。
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, surrealist, full body, by Stanley Artgerm L and Alphonse Mucha
我们可以看到这两种艺术家的绘画风格融合出来的效果非常好。翻译注:慕夏是非常有名的画家,在我这个非专业人士的认知中他可以算是塔罗牌画风的创始人了,其绘画有很突出的古典、巴洛克、平面风格,另外一位画家不熟。在生成的示例图中可以看到慕夏风格表现的十分显著,这里我在制作示例图的时候把闪电的英文拼错了,所以你可以看到生成图中基本没有闪电了,不过因为慕夏+艾玛实在有点好看,我也就不修改了
网站名(Website)
收集网站像 Artstation 和 Deviant Art 里聚集了大量的有明确流派的。 添加这类关键词可以使我们的输出结果趋同于网站上的图像艺术风格。
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, surrealist, full body, by Stanley Artgerm L and Alphonse Mucha, artstation
看起来变化不大,但是生成的确实看起来像你能从Artstation上找到的图。翻译注:在复刻的过程中我并不确定作者所说的Website是个有效的关键词类别,当我在webui中输入artstation时,token数量从43变成了45,非常怀疑模型把它拆分为art和station两个单词作为输入处理了(原因见文章后面的“指令可以有多长”章节)。另外网站的画风本身就是多元的,我也不太能理解他会对输出结果产生怎样的影响,在后续的示例中我会删除该关键词,以防止其造成不好的影响。至于与上一节相比,闪电又有了,那只是因为我把lightning拼写修改正确了
清晰度(Resolution)
清晰度代表了输出的图像的锐度与细节度。我们尝试添加这两个关键词:highly detailed,sharp focus。
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm L and Alphonse Mucha, artstation, highly detailed, sharp focus
好吧,看上去没有太大的效果,应该是之前的已经很锐化且细节化了,但是添加上也并无坏处。
细节描述(Additional details)
细节描述是调整的调味剂。我们尝试添加 sci-fi(科幻), stunningly betiful(绝美)与 dystopian (反乌托邦)来对图像进行一些调整。
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm L and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly betiful, dystopian
颜色(Color)
通过添加颜色关键字,你可以控制图像整体的色彩。你所添加的颜色有可能作为图像整体的色调,或某个物体的颜色。
我们尝试使用关键词 idescent gold来为图像添加一点金色。
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm L and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly betiful, dystopian, idescent gold
金色的效果很不错!
光照(Lighting)
所有摄影师都会告诉你,出片的要素之一就是光照。光照关键字对于生成的也有着巨大的影响。我们尝试一下在指令中添加cinematic lighting 与 dark
Emma Watson as a powerful mysteous sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm L and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly betiful, dystopian, idescent gold, cinematic lighting, dark
以上我们完成了整个演示demo的提示指令的构建
总结
可能你注意到了,仅仅向基的目标对象再添加几个关键关键词(keywords)就已经可以生成出不错的图像出来了。对于构建Stable Diffusion的输入指令来说,通常你并不需要添加太多的关键词
否定提示指令 (Negative pmpt)
否定提示指令 是另一个非常有效的调整图像的输入,通过输入你不想要的内容,而不是想要的,来实现对图像的调整。否定提示指令并非只能排除实体对象,也可以是风格或者其他一些不想要的图像特征(比如:难看(ugly),异型(deformed))
如果你使用的是SD的二代模型版本的话(注:目前大部分人使用的是1.4/1.5的一代模型版本),否定提示指令是一个必填项,否则你会得到与一代版本相比差的多的图像。对于一代版本来说,否定指令是可选的,不过在实际使用时都会对其进行设置,毕竟否定指令即使没有提升图像的效果,也不会对其造成什么损害。
我将使用一个通用的否定提示指令。有关其原理与更详细的使用方式,你可以在这篇文章中进行深入了解。
ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra li, diigured, deformed, body out of frame, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, , distorted face, blurry, draft, grainy
可以看出否定提示指令使得图像中的主体更加凸显,不会显得过于平面化。
构建良好指令的流程
迭代构建
你应该使用迭代的过程来构建提示指令,就像前面的示例所演示的,随着关键字逐一添加到主体中,我们最终可以生成非常棒的。
我总是从只包含主体(Subject)、介质(Medium)、与风格(Style)关键词的简单指令开始进行构建。生成至少4张来观察结果。大部分这样的基指令并不是能100%起效的。你需要对你所使用的基关键词能获得什么有一些统计学上的感知。
迭代过程中一次最多添加2个关键词,同样生成至少4张来观察其效果
使用否定提示指令
使用通用否定提示指令永远是个不会出错的开始。
添加关键词到否定提示指令中也是迭代话构建的一部分。这些否定关键词可以是你希望避免在图像中生成的物体、或者身体部位。(由于一代模型并不太善于渲染手部,通过在否定指令中添加“hand”关键词以在图像中将其直接隐藏也是个不错的选择)
提示指令书写技巧
你可以调整一个关键词的影响因子,也可以控制在特定的生成步数(sampling step)后切换关键词。
下面所介绍的语法都可以在 AUTOMATIC111 GUI 翻译注:就是stable-diffusion-webui中进行使用。你可以在 Colab notebook 上使用这个工具,也可以将其部署到本地的 Windows 或 Mac 电脑上。
关键词权重
(这个语法可以在webui中使用)
你可以使用`(关键词: 权重)`这个语法来控制关键词的影响因子。权重是一个数值,小于1代表其重要度较低,大于1代表其重要度更高。
比如,我们可以在下面的指令中对狗这个关键词添加权重
dog, tumn in pas, ornate, betiful, atmosphere, vibe, mist, smoke, fire, chimney, rain, wet, pstine, puddles, melting, ing, snow, creek, lush, ice, bdge, forest, ses, flowers, by stanley artgerm l, greg rutkowski, thomas kindkade, alphonse mucha, loish, norman ckwell.
添加狗的权重导致图像中出现了更多的狗,而反之则减少。并不是对于所有权重起到的都是这样的效果,但是绝大多数情况下,你都可以预期权重会产生这样的效果。
这个技巧不仅可以使用在主体关键词上,对所有关键词类别例如风格或光照都可以使用。
与[]语法
(这个语法可以在webui中使用)
与[]是与调整关键词权重等价的语法。`(关键词)`会将括弧中的关键词权重增加1.1倍,其等价于`(关键词:1.1)`。`[关键词]`将括弧中的关键词权重调低至0.9倍,其等价于`(关键词:0.9)`。
你可以像代数公式一样使用多个括弧来倍增其权重影响效果
(keyword):1.1
((keyword)):1.21
(((keyword))):1.33
与之相似的,使用多个中括弧的效果如下:
[keyword]: 0.9
[[keyword]]: 0.81
[[[keyword]]]: 0.73
关键词混合
(这个语法可以在webui中使用)
你可以混合两个关键词,这种用法准确的来说称作指令调度(pmpt scheng)。语法如下:
[关键词1:关键词2:影响因子]
`影响因子` 控制在采样的哪一步(step)中提示指令中的关键词1会切换到关键词2,它是一个0到1之间的参数
比如使用如下的指令
Oil painting portrait of [Joe Biden:Donald Trump:0.5]
将输入的step参数设置为30
这意味着在生成过程的前15步使用的是下面的指令
Oil painting portrait of Joe Biden
而在接下来第16到30步的生成过程中指令将变成下面这样
Oil painting portrait of Donald Trump
影响因子参数将决定关键词在何时发生变化,在上面的例子中它将在 30 steps x 0.5 = 15 steps后执行。
调整影响因子所产生的效果可以看作是将两位总统的肖像在不同程度上进行混合。
你也许注意到Trump身着白色西服更想是Biden的服饰搭配,这其实非常好的展现了使用关键词混合中很重要的一个规则:关键词1决定了总体的混合效果。越前的diffusion生成步骤越对图像整体的混合结果产生影响,而较后的生成步骤则只负责逐渐改进细节。
小测试:如果在上面的例子中将Joe Biden与Donald Trump调换顺序,你觉得对于生成的会产生什么影响呢?
面部混合
关键词混合的常用于借用两个不同的明星来创建出新的面容。举例来说,[Emma Watson: Amber heard: 0.85],40 steps,将会产生一个介于二者之间的面孔:
[Emma Watson: Amber heard: 0.85] oil painting, blur backgund, elegant
选择两个合适的名字再加上调整参数,就可以获得我们想要的样貌。
破产版pmpt-to-pmpt
使用关键词混合,你可以获得到类似于 pmpt-to-pmpt 的效果,即通过编辑生成出一对高度相似的图像。下面的两张图像使用了同样的提示指令,除了使用指令调度语法将苹果替换为了火焰,两张图的seed与steps参数设置也是一样的翻译注:这里使用的示例是我自己做的,与原文不一致,提示指令改成了将苹果替换成了火球,主要原因是替换成火焰没有做出太好的效果图来
[Emma Watson: Amber heard: 0.75] holding an [apple: fire ball:0.9], shining h depth of field backgund, classic, oil painting, portrait, elegant, upper class, red lips, ear weang. Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 6, Seed: 805277495
混合因子需要精细的调整。它具体是如何工作的?其背后的理论其实就是:输出图像的整体效果是由早期的扩散过程(diffusion pcess)决定的。当扩散过程开始聚焦于更小的区域时,切换任何的关键词都不会对图像的整体结果产生较大的影响。这使得这种方式可以仅仅改变图像中的一小部分。
指令可以有多长?
指令长度取决于你使用的是哪个Stable Diffusion应用,应用中可能会对你指令(pmpt)中的关键词(keyword)数量进行限制。在SD一代的基版本中,指令的限制是75个词元(token)
需要注意的是词元(token)并不等同于单词(word)。SD所使用的 CLIP模型 会自动将提示指令为一组词元,即该模型所知晓的单词的数字表示。如果你使用了该模型所不知道的单词或词组,该单词将会被切分为两个或更多的子单词(sub-words)直到他知道每个单词的含义。因此能够被CLIP模型所认知的单词(word)才被称为词元(token),举例来说`dream`是一个词元,`beach`是一个词元,但是`dreambeach`是两个词元,因为CLIP模型并不知道这个单
caht gpt全称:Chat Generative Pre-trained Tranormer
1. chatT介绍
chatT是由OpenAI开发的一个人工智能聊天机器人程序,于2022年11月推出。该程序使用基于T-3.5架构的大型语言模型并通过强化学习进行训练。
ChatT目前仍以文字方式交互,而除了可以通过人类自然对话方式进行交互,还可以用于相对复杂的语言工作,包括自动文本生成、自动问答、自动摘要等在内的多种任务。
如:在自动文本生成方面,ChatT可以根据输入的文本自动生成类似的文本(剧本、歌曲、企划等),在自动问答方面,ChatT可以根据输入的问题自动生成答案。还具有编写和调试计算机程序的能力。
在推广期间,所有人可以免费注册,并在登录后免费使用ChatT实现与AI机器人对话。
ChatT可以写出相似于真人程度的文章,并因其在许多知识领域给出详细的回答和清晰的答案而迅速获得关注,证明了从前认为不会被AI取代的知识型工作它也足以胜任,对于金融与白领人力市场的冲击相当大,但其事实准确参差不齐被认为是一重大缺陷,
其基于意识形态的模型训练结果并被认为需要小心地校正。ChatT于2022年11月发布后,OpenAI估值已涨至290亿美元[7]。上线两个月后,用户数量达到1亿。
2. chatT如何训练数据
ChatT使用基于人类反馈的学习和强化学习在 T-3.5 之上进行了微调。这两种方法都使用了人类训练员来提高模型的能, 通过人类干预以增强机器学习的效果,从而获得更为真的结果。
在学习的情况下,模型被提供了这样一些对话, 在对话中训练师j充当用户和AI两种角色。在强化步骤中,人类训练员首先对模型在先前对话中创建的响应进行评级。
这些级别用于创建“奖励模型”, 使用近端策略优化(Pximal Policy Optimization-PPO)的多次迭代进一步微调。
这种策略优化算法比信任域策略优化(trust region policy optimization)算法更为高效。这些模型是与 Micsoft合作,在其Micsoft Azure超级计算基设施上训练的。
此外,OpenAI继续从ChatT用户那里收集数据,这些数据可用于进一步训练和微调 ChatT。 允许用户对他们从ChatT收到的回复投赞成票或反对票;在投赞成票或反对票时,他们还可以填写一个带有额外反馈的文本字段。
ChatT的训练数据包括各种文档以及关于互联网、编程语言等各类知识,如BBS和Python编程语言。
关于ChatT编写和调试计算机程序的能力的训练, 由于深度学习模型不懂编程,与所有其他基于深度学习的语言模型一样,只是在获取代码片段之间的统计相关。
以上内容就是对于怎么用ChatGPT生成图片AI绘图资讯全部了,希望能够帮助网友们!更广泛丰富文章请继续关注神奇下载HtTPs://wWw.sqxzZ.Com,您的支持,我们会更加努力更新!
相关文章